Unlocking Advanced Retrieval with RAG Fusion
Last week, we explored how Retrieval-Augmented Generation (RAG) enhances generative AI by bridging the gap between static training data and real-world, domain-specific information. RAG's dynamic integration of private and up-to-date data through technologies like vector embeddings enables precise and contextually relevant responses. This approach overcomes the limitations of static models without the costs of fine-tuning, making it ideal for applications where accuracy and specificity matter most.
In the world of AI-powered search and retrieval, Retrieval-Augmented Generation (RAG) has become a cornerstone of creating responsive, knowledge-driven systems. Today, we’ll explore how advancements like Multi-Query and Reciprocal Ranking elevate RAG’s capabilities and help you retrieve more precise and meaningful results.

RAG with a Single Query
RAG operates by leveraging a retriever model to fetch relevant documents from a private dataset, followed by a generator model that synthesizes responses. In its simplest form, a single query is issued, yielding a ranked result set. While effective, this approach can struggle with edge cases like ambiguous queries or sparse datasets, potentially missing valuable context or diversity.
Multi-Query: A Smarter Approach
Multi-Query builds on the single-query method by generating multiple variations of the original query. These variations are tailored to uncover diverse perspectives or more granular details within the dataset. By merging the results, Multi-Query provides a richer and more robust foundation for downstream generation.
Why Multi-Query Matters:
- It mitigates blind spots by probing the dataset from multiple angles.
- It reduces over-reliance on a single query's semantic framing, improving recall.
- It ensures that edge cases and diverse interpretations are better represented.
Reciprocal Ranking: Refining Scores with Mathematical Precision
Once Multi-Query retrieves results, how do we consolidate and rank them meaningfully? This is where Reciprocal Ranking shines. The formula:
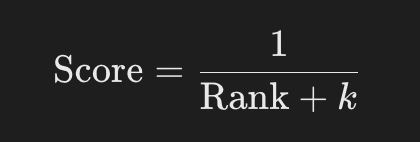
assigns each retrieved item a score based on its rank in the result set. The smoothing constant k plays a crucial role in avoiding exaggerated impacts of top-ranking items (especially when k > 0).
Key Takeaways About k:
- Smaller values make high-ranking items more dominant in the final score.
- Larger values create a more uniform impact across rankings.
By carefully tuning k, we can strike a balance between prioritizing top results and maintaining diversity.
Scoring and Fusion: Assigning Final Ranks
Let’s apply Reciprocal Ranking to a private dataset. After generating multiple queries and retrieving results, each document is assigned a score based on its position in the rankings. These individual scores are aggregated across all queries to compute a Fusion Score for each document.
The final step? Sorting by Fusion Score to create a holistic ranking that reflects the collective insights of the Multi-Query process.
Recap: How It All Comes Together
- RAG with a single query works well but has limitations in recall and diversity.
- Multi-Query improves retrieval by exploring multiple interpretations of a query.
- Reciprocal Ranking provides a mathematically sound method for scoring and fusion.
By combining these techniques, you can unlock deeper insights from your datasets, ensuring better coverage and precision in results.

Explore More
Want to dive deeper into this and other ways AI can elevate your web apps? Our AI-Driven Laravel course and newsletter covers this and so much more!
👉 Check Out the Course: aidrivenlaravel.com
If you’ve missed previous newsletters, we got you: aidrivenlaravel.com/newsletters
Thanks for being part of our community! We’re here to help you build smarter, AI-powered apps, and we can’t wait to share more with you next week.
Stay connected
Get course updates
AI-Driven Laravel course is currently in active development and will be launching soon! Stay ahead of the curve by signing up for updates below. Be the first to know about the latest news, release date, early access opportunities, and exclusive offers!
© 2025 Vehikl